Mechanistic Analysis of Induction in a Tiny Transformer
Overview
This project investigates how correct model behaviour can emerge from unexpected internal strategies. I designed a mechanistic interpretability study to analyse how a small transformer solves a synthetic periodic induction task.
Although the model achieved perfect prediction accuracy, analysis revealed that it did not learn the expected induction circuit. Instead, it relied on a position-dependent shortcut, supported by diffuse recency-biased attention patterns.
This demonstrates that behavioural success does not guarantee that a model has learned the intended mechanism, and that internal strategies can differ in ways that may affect reliability and generalisation.
Problem
Transformers trained on repeated-sequence tasks are often assumed to develop induction heads—attention circuits that copy tokens from earlier positions.
However, strong behavioural performance does not guarantee that the underlying mechanism matches this expectation.
The objective of this project was to determine how the model actually solves the task, and whether correct outputs can arise from alternative, potentially less robust internal strategies.
Task Setup
Synthetic periodic induction dataset:
- Vocabulary size: 20
- Sequence length: 32
- Pattern length: 8
- 4 repeated pattern blocks per sequence
Example sequence:
[A B C D E F G H A B C D E F G H A B C D E F G H …]
Model architecture:
- Decoder-only Transformer
- 2 layers
- 4 attention heads
- Hidden size: 64
- MLP size: 256
Training objective: autoregressive next-token prediction.
Methodology
Two complementary approaches were used to analyse the model’s internal behaviour:
Attention Probing
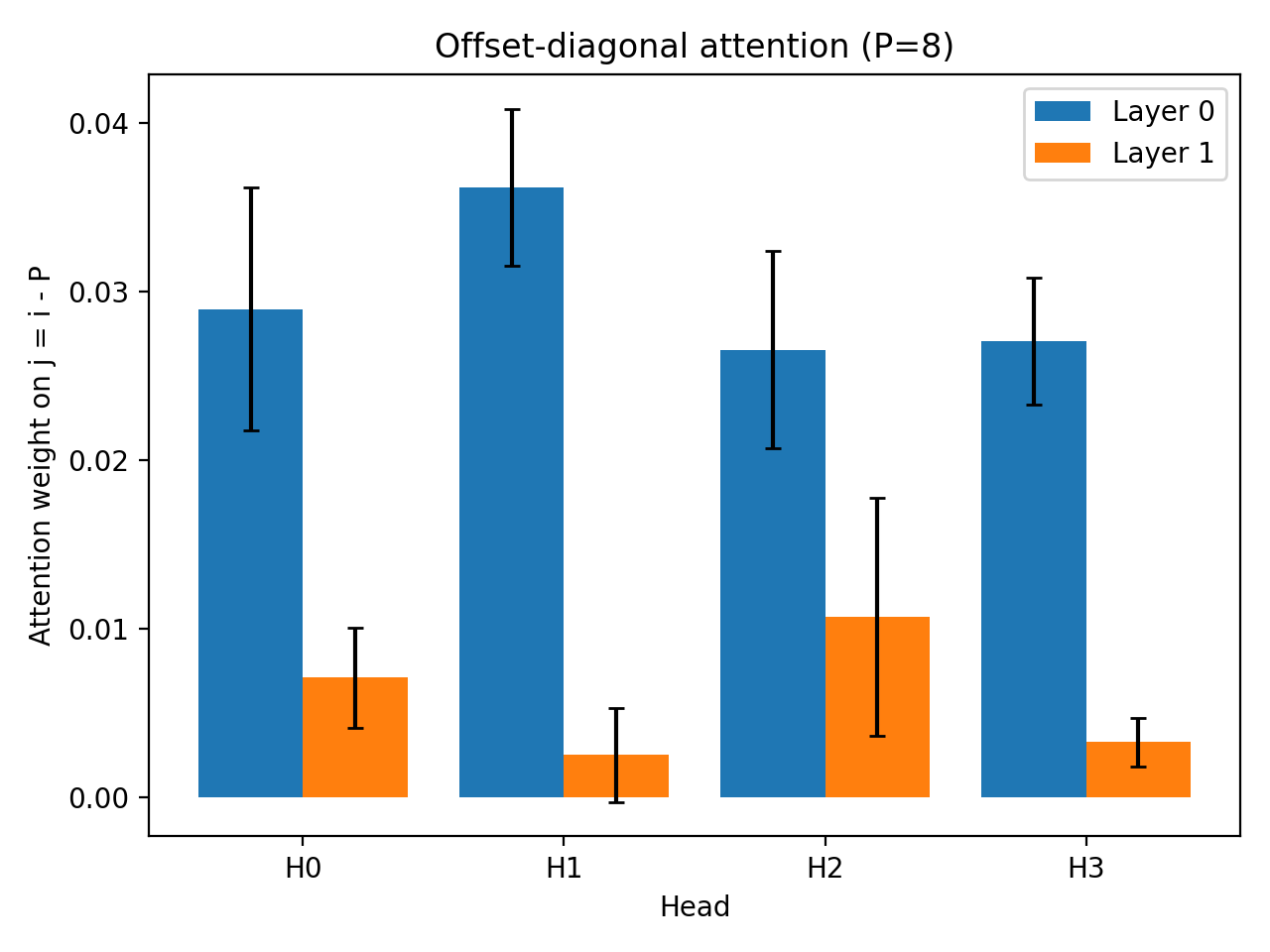
Measured whether the model attends to the expected induction offset $( j = i - P)$.
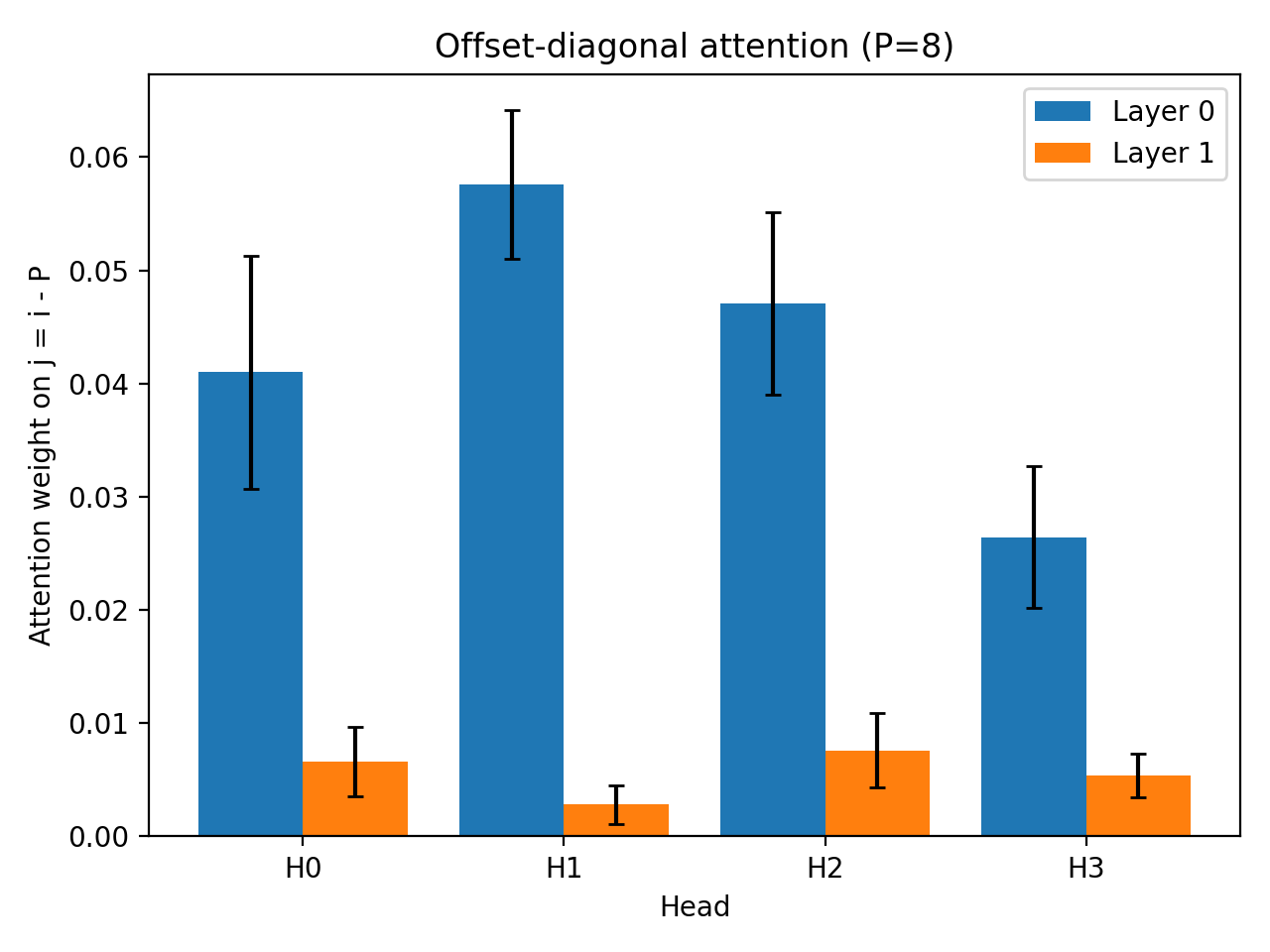
Despite perfect task performance, attention weights remained close to a uniform-attention baseline, indicating the absence of a strong induction head. Heatmaps showed diffuse recency-biased attention rather than a clear induction diagonal.
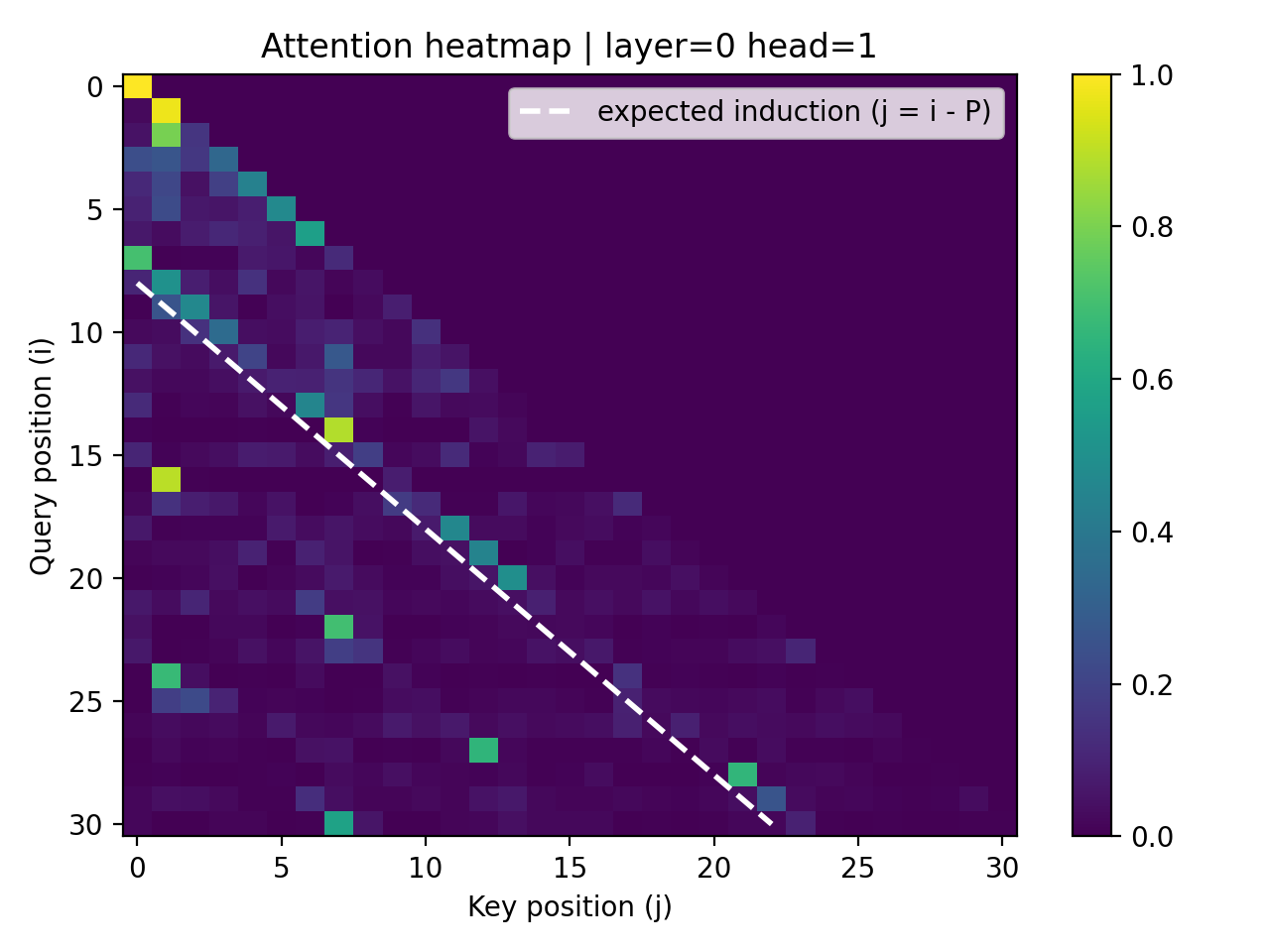
Intervention Experiments
To test causal dependencies in the learned strategy:
- Positional Ablation: Removing positional embeddings caused accuracy to collapse to near-random performance, showing strong dependence on positional signals.
- Phase Rotation: Cyclic sequence shifts had no effect, indicating the model does not rely on fixed phase alignment.
- Prefix Perturbation: Random prefixes preserved performance, suggesting the strategy is not anchored to sequence start.
Key Findings
- Perfect behavioural performance does not imply that the expected mechanism has been learned.
- Attention patterns remained diffuse and recency-biased, rather than aligned with induction offsets.
- The model relied heavily on positional information, rather than token copying.
- The task was solved via a position-dependent shortcut, not the intended algorithm.
These results show that models can produce correct outputs while relying on unexpected and potentially fragile internal strategies, reinforcing the importance of analysing internal behaviour alongside performance metrics.
Why This Matters
This project highlights a broader issue in evaluating AI systems: correct outputs do not necessarily reflect correct reasoning or robust internal behaviour. Even in simple settings, models can rely on shortcuts that may fail under distribution shift or task variation.
Understanding these mismatches is important for building systems that are not only accurate, but also reliable and interpretable in more complex, real-world settings.
Technologies
PyTorch, Matplotlib, Weights & Biases