Evaluating Reliability in a Multimodal Medical QA System with RAG
Overview
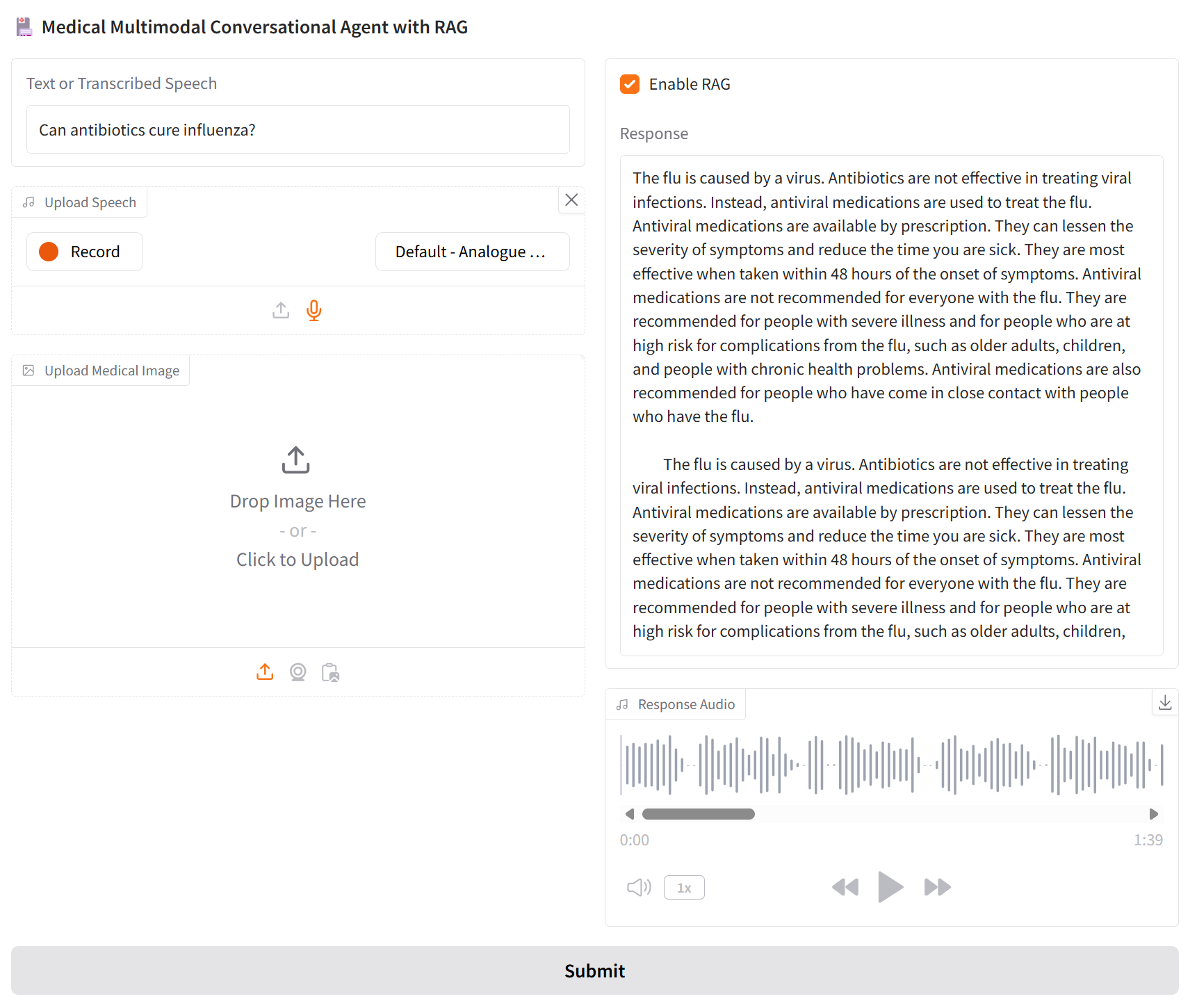
This project investigates how retrieval-augmented generation (RAG) affects the reliability of a multimodal medical question-answering system. I led a team in designing and evaluating a conversational agent grounded in NHS Inform Scotland data.
The focus was not only on building the system, but on analysing how grounding changes model behaviour, particularly in a safety-critical domain where incorrect responses can have real consequences.
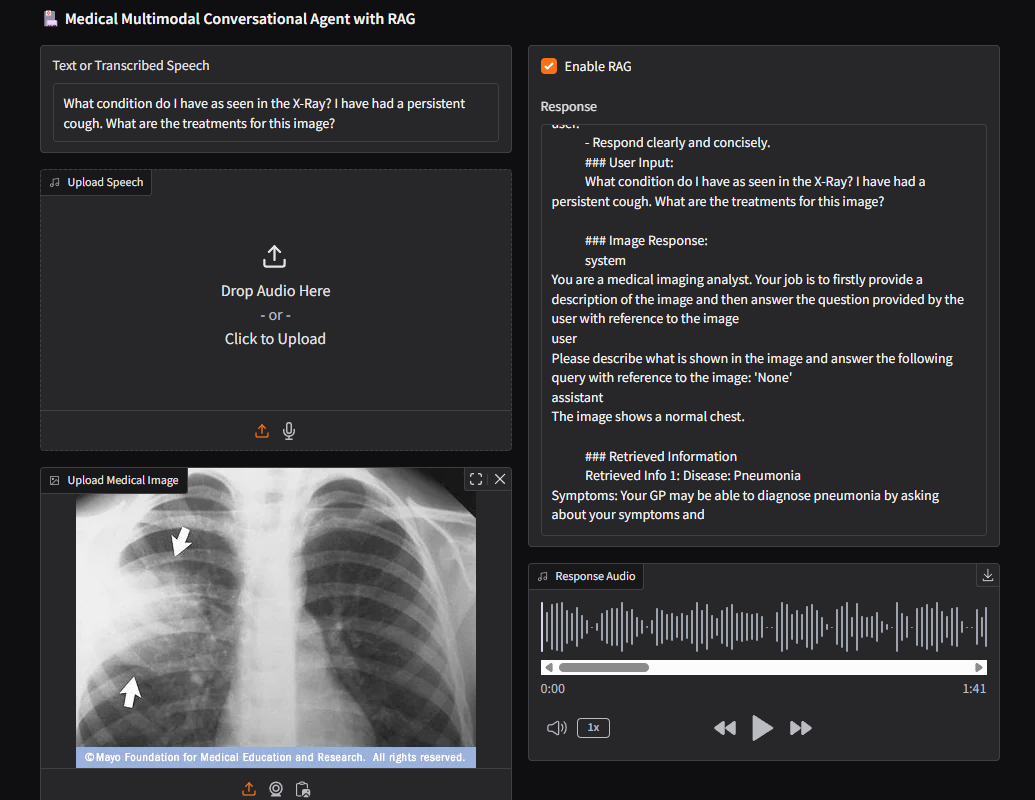
The system integrates text, speech, and a proof-of-concept visual pipeline to explore how multimodal interaction and retrieval affect both accuracy and usability.
Problem
Large language models can produce fluent medical responses, but these may be inaccurate, unsupported, or misleading.
A key question is whether retrieval-augmented generation improves factual reliability, and what trade-offs it introduces in system behaviour, such as latency, formatting, and usability.
This project evaluates how grounding affects both accuracy and practical deployment characteristics in a multimodal setting.
Methodology
Core QA System
- Fine-tuned Llama-3.1-8B for medical QA using MedQA
- Built a FAISS-based retrieval system over NHS Inform Scotland
- Generated embeddings with MiniLM
- Compared model behaviour with and without RAG
Multimodal Integration
- Integrated Whisper for speech input
- Developed a tri-modal pipeline including visual input via a vision-language model
Evaluation Design
- Compared RAG vs non-RAG across intrinsic metrics (BLEU, ROUGE, BERTScore)
- Analysed semantic similarity to reference NHS responses
- Conducted qualitative evaluation of factual correctness and usability issues
Key Results
- RAG improved semantic alignment with reference answers:
- BERTScore: 0.7892 → 0.8333 (+5.6%)
- BLEU and ROUGE improved only marginally, indicating limited gains in surface-level fluency
- Without RAG, the system produced factually incorrect or unsupported responses
- With RAG, factual reliability improved, but new issues emerged:
- formatting inconsistencies
- repetitive hyperlinks
- increased latency
These results show that grounding improves factual correctness but introduces new system-level trade-offs, particularly in usability and response quality.
Limitations & Trade-offs
- RAG improved semantic accuracy but had limited impact on fluency
- Responses could remain difficult for non-expert users due to medical terminology
- Retrieval introduced latency and formatting inconsistencies
- Multimodal pipeline was not formally evaluated due to lack of suitable datasets
- Knowledge base was limited to NHS Inform Scotland content
Why This Matters
This project highlights a broader challenge in deploying AI systems in real-world settings: improving one aspect of performance (factual grounding) can introduce new failure modes in usability and system behaviour.
In safety-critical domains such as healthcare, evaluating reliability requires going beyond accuracy metrics to consider how systems behave under realistic interaction conditions.
Technologies
Llama 3.1, FAISS, MiniLM, Whisper, Qwen2-VL, PyTorch, Gradio