AI Learning Buddy – RAG-Based Academic Assistant (Proof of Concept)
Overview
I designed and deployed a retrieval-augmented “Learning Buddy” to support university students by answering course-specific questions grounded in official materials.
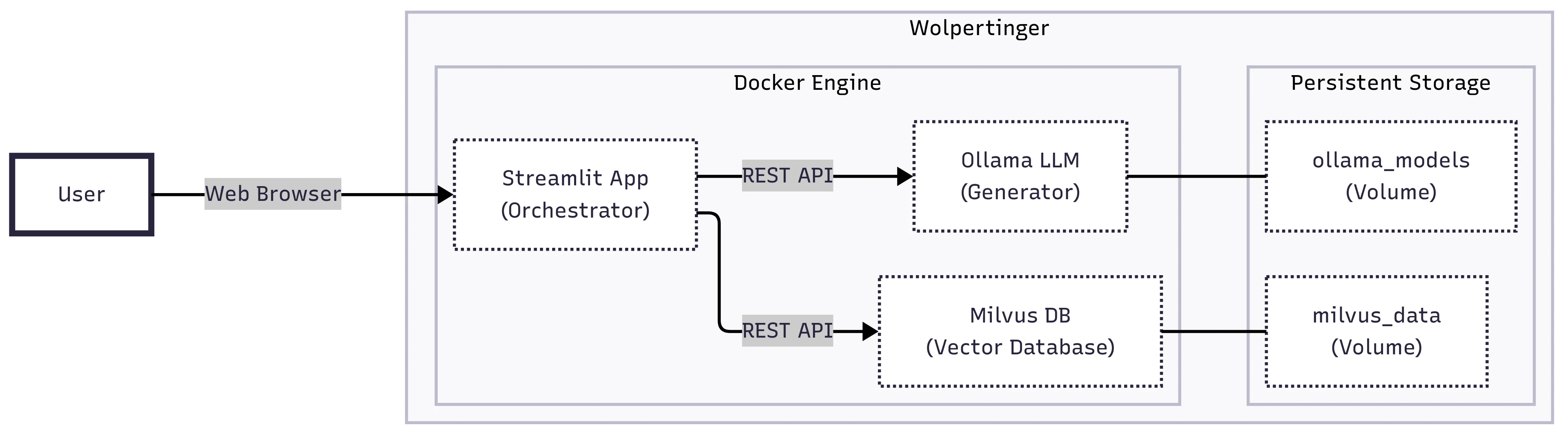
The system was implemented as a containerized, local-first solution and deployed on a university-managed server, enabling end-to-end testing under realistic usage conditions.
This project focused on building a robust, modular RAG system and observing how it performs across different courses, query types, and document structures.
Problem
Students often need to extract precise information from large volumes of course documentation.
The goal was to build a document-grounded assistant that could provide accurate, course-specific answers while preserving data privacy, and to understand how such a system performs across different types of queries and content formats.
Methodology
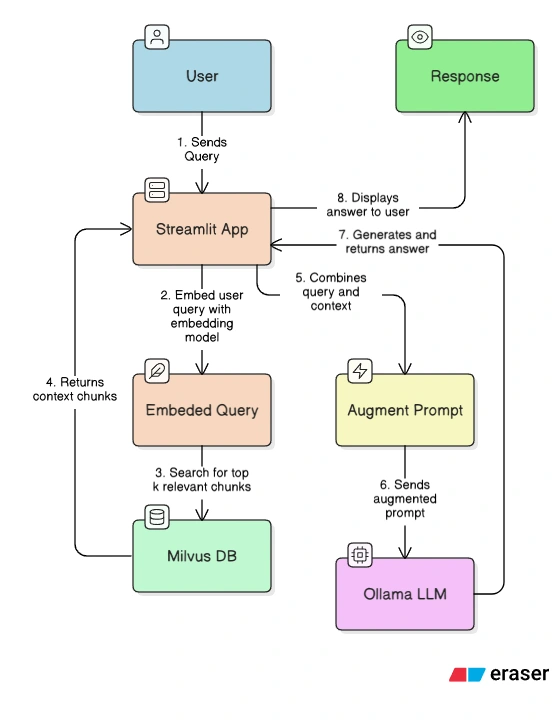
System Architecture
- Document ingestion pipeline (PDF → Markdown → structured JSON)
- Semantic embeddings using BAAI/bge-small-en-v1.5
- Vector search via Milvus
- Local LLaMA 3 model served through Ollama
- Streamlit interface with Docker Compose orchestration
Key Design Decisions
- Course-level data isolation using
course_idfiltering - Fully local deployment to eliminate reliance on external APIs
- Modular ingestion → embedding → indexing → retrieval pipeline
- Structured testing using curated query sets
Key Results
- Achieved 75% accuracy (F21CA) and 77% accuracy (F21NL) across evaluated queries
- Performance varied significantly by query type:
- strong on out-of-scope and policy queries
- weaker on factual and multi-turn queries
- System behaviour differed across courses despite similar overall accuracy
- Document structure had a major impact on performance:
- poorly formatted documents reduced accuracy
- well-structured documents improved retrieval quality
These results highlight that RAG system performance depends heavily on data quality, query structure, and retrieval design—not just the underlying model.
Limitations & Trade-offs
- Limited to a single-server deployment
- Manual ingestion pipeline is not suitable for dynamic updates
- Hallucinations reduced but not eliminated
- Performance depends strongly on document formatting and quality
Technologies
LLaMA 3, Milvus, Docker, Streamlit, Hugging Face
Workflow